Итак, для ME.BECS (https://github.com/chromealex/ME.BECS) я начал писать поиск пути, ну вот который из коробки там будет.
Для этого я поставил несколько условий:
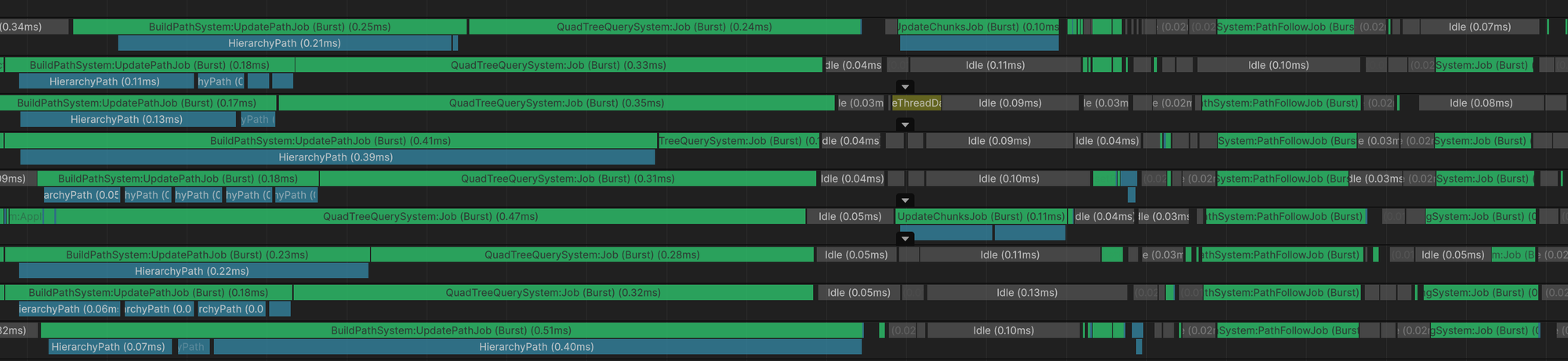
1. Все максимально должно быть burst + многопоточно (ну собственно как и ME.BECS)
2. От количества юнитов производительность зависит минимально
3. Много динамических препятствий
4. Юниты могут толкаться и обходить друг друга без необходимости перестраивать путь
5. Мир может быть довольно большим
Введение
Те, кто читают мой канал https://t.me/unsafecsharp, знают, что для реализации задуманного подходит алгоритм Flow Field.
На самом деле с ним все хорошо, кроме того, что его стоимость W * H, то есть если у нас карта 100х100, то нужно будет обойти 10000 нод. А если 500х500, то уже 250000. Несомненный плюс в том, что перестраивать путь не нужно и количество юнитов ограничено лишь производительностью их алгоритма перемещения.
Общая идея заключается в том, чтобы объединить два подхода: A* и FlowField.
Для начала разделим все пространство на чанки (размер каждого чанка возьмем, например, 20х20).
Между чанками найдем все пересекающиеся ноды, т.е. те ноды, которые проходимые и их соседи принадлежат другому чанку. Таким образом, получаем некие переходы между чанками, будем называть их порталами (а локальными порталами - порталы, принадлежащие одному чанку).
Первый этап - обновление графа
На самом деле вы можете подумать, а почему обновление, а где построение? И это правильный вопрос, но ответ на него в пункте 3 (много динамических препятствий). По сути если мы сделаем полностью динамический мир - стоимость должна быть такой же как и со статическим.
Итак, вернемся :)
Необходимо построить путь от каждого локального портала во все другие локальные порталы. Для этого будем использовать алгоритм А* или dijkstra (в этом случае не принципиально). Если путь найден - значит из портала можно выйти в другой портал. Если порталы соединяются в одну цепочку - этой цепочке присваивается уникальный айдишник Area (оно пригодится чуть позже).
Стоимость этого перехода будет равна длине найденого пути. Эту операцию можно отнести к разряду редких, т.к. выполняться должна только в случае изменения чанка (например, в чанке появляется или исчезает препятствие).
Мы получим 2 графа: верхнего уровня и нижнего.
Граф верхнего уровня - это граф (у пустого поля каждый чанк имеет 4 ноды), соединяющий чанки.
Граф нижнего уровня - это сами чанки, а каждый чанк - это по сути отдельный граф 20х20 нод.

Пустой чанк
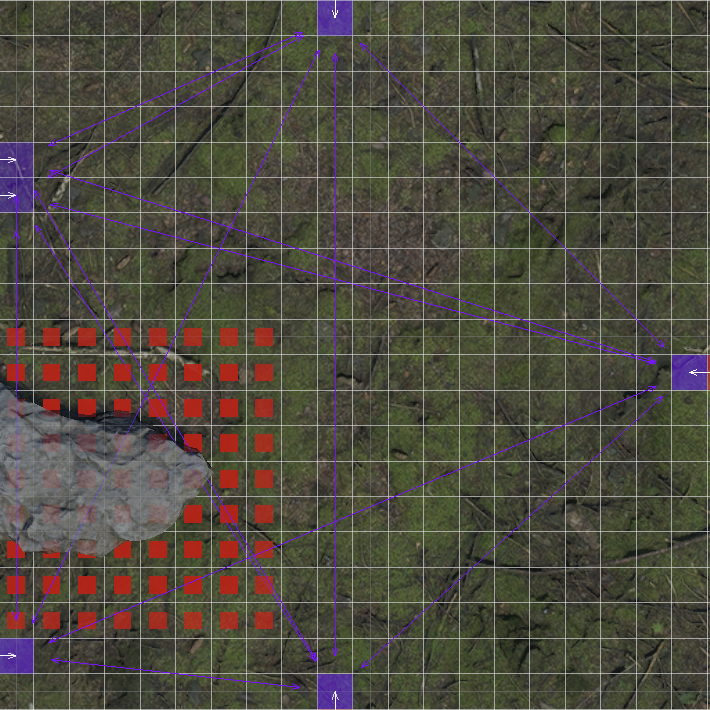
Чанк с препятствием
Обновлять чанки мы будем только те, которые изменяются, когда в них добавляется объект, меняющий свойства нод.
Второй этап - обновление пути
Вы спросите, а почему... Ну камон, мы это уже проходили :)
Теперь мы готовы строить (пардон, обновлять) наш путь. В отличие от Flow Field (где не важна точка старта), нам все же нужны точки старта. Но нам нужно собрать информацию обо всех стартовых точках и для каждой начальной точки получить чанк. И вот список уникальных чанков - это и есть наши точки старта.
Т.е. если у нас 1000 юнитов находятся в одном чанке, то поиск пути сработает для всех один раз. Если они занимают разные чанки, будем искать от каждого. Значит стоимость будет O(n).
Этап первый - найти путь на верхнем графе, это будет довольно быстро, т.к. нод в верхнем графе совсем немного. Путь ищем от каждого чанка до конечного чанка.
Этап второй - обработать каждый чанк и построить Flow Field. По сути тут типичное построение: начиная с конечной точки (мы выдаем ей стоимость 0) начинаем расходиться в 4 стороны и увеличивать стоимость на размер ноды, при этом стоимость непроходимых нод максимальная, а промежуточные значения - это зоны меньшей проходимости. В итоге получим поле со стоимостями. В этом же проходе мы можем рассчитать LoS (Line of Sight - прямой обзор до конечной точки). Следующим шагом нужно рассчитать направление: берем каждую ноду и считаем минимальную стоимость проходя 8 соседей. Где минимальная стоимость - туда и смотрим. Таким образом мы получаем Flow Field, но он получается строго направленный.
Чтобы сгладить направления, я придумал увеличивать стоимость не на размер ноды, а на дистанцию до цели. Таким образом ноды, которые находятся не на линии конечной точки будут иметь расходящиеся веса. А при вычислении направления мы учитываем веса соседних нод, чтобы определить куда повернуть направление.
Так выглядит Flow Field
Поддержка юнитов разных размеров
На самом деле тут все стандартно: строим не один граф, а несколько графов, накладываем друг на друга, а вокруг препятствий увеличиваем радиус агента.
Высоты
Я добавил для каждой ноды не только стоимость, но и высоту, тем самым получил возможность двигать агентов, меняя их позицию по высоте. У агента есть параметр max slope, с помощью которого мы рассчитываем проходимость ноды, если высота отличается больше, чем на этот угол.
Результат
Для каждого юнита мы находим ноду, на которой он стоит и двигаем его по направлению, которое записано в этой ноде. Тут мы можем добавить steering, т.к. нас в принципе мало интересует где находится юнит в данный момент. Толкают его в сторону - он все равно знает направление, по которому ему нужно следовать.
Дополнительно я записываю в кеш данные по flow field от портала к порталу, чтобы при построении нового пути можно было их переиспользовать.